GRB 950830 Nature script¶
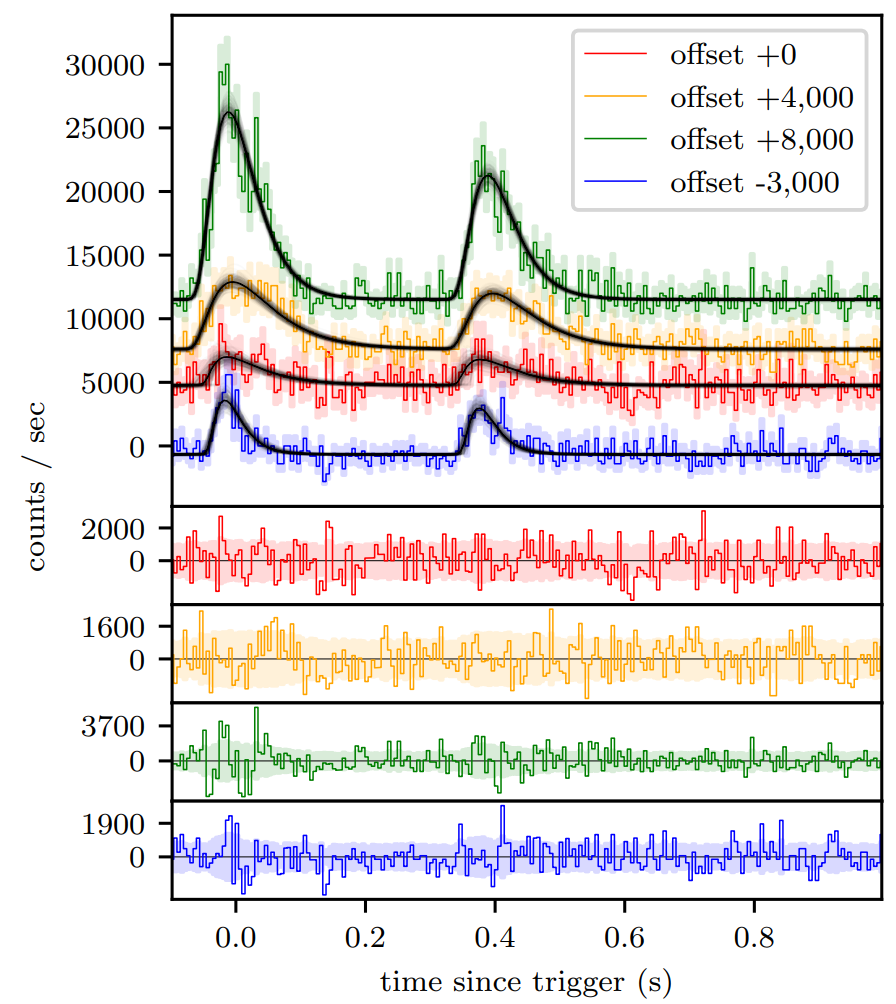
BATSE trigger 3770 with FRED lens fit.¶
gravlensnature.py¶
import sys, os
import argparse
from PyGRB.main.fitpulse import PulseFitter
from PyGRB.backend.makemodels import create_model_from_key
def main_two_pulse_models():
""" These are the most relevant models to the analysis of GRB 950830. """
lens_keys = ['FL', 'FsL', 'XL', 'XsL']
null_keys = ['FF', 'FsFs', 'XX', 'XsXs']
keys = lens_keys + null_keys
model_dict = {}
for key in keys:
model_dict[key] = create_model_from_key(key)
return model_dict
def load_3770(sampler = 'dynesty', nSamples = 100, **kwargs):
test = PulseFitter(3770, times = (-.1, 1),
datatype = 'tte', nSamples = nSamples, sampler = sampler,
priors_pulse_start = -.1, priors_pulse_end = 0.5,
priors_td_lo = 0.2, priors_td_hi = 0.5, **kwargs)
return test
def analysis_for_3770(indices):
""" Use this function to send each job permutation to a different CPU. """
num_samples = [500, 2000, 4500]
for samples in num_samples:
GRB = load_3770(sampler = SAMPLER, nSamples = samples)
GRB.offsets = [0, 4000, 8000, -3000]
model_dict = main_two_pulse_models()
models = [model for key, model in model_dict.items()]
GRB._split_array_job_to_4_channels( models = models,
indices = indices,
channels = channels)
def evidence_for_3770(**kwargs):
num_samples = [500, 2000, 4500]
for samples in num_samples:
GRB = load_3770(sampler = SAMPLER, nSamples = samples, **kwargs)
GRB.offsets = [0, 4000, 8000, -3000]
model_dict = main_two_pulse_models()
models = [model for key, model in model_dict.items()]
for model in models:
GRB.get_residuals(channels = [0, 1, 2, 3], model = model)
lens_bounds = [(0.37, 0.42), (0.60, 1.8)]
GRB.lens_calc(model = model, lens_bounds = lens_bounds)
GRB.get_evidence_from_models(model_dict = model_dict)
if __name__ == '__main__':
parser = argparse.ArgumentParser( description = 'Core bilby wrapper')
parser.add_argument('--HPC', action = 'store_true',
help = 'Are you running this on a cluster?')
parser.add_argument('-i', '--indices', type=int, nargs='+',
help='an integer for indexing model/channel')
args = parser.parse_args()
HPC = args.HPC
if not HPC:
# run the later analysis on a local machine
from matplotlib import rc
rc('font', **{'family': 'DejaVu Sans',
'serif': ['Computer Modern'],'size': 8})
rc('text', usetex=True)
rc('text.latex',
preamble=r'\usepackage{amsmath}\usepackage{amssymb}\usepackage{amsfonts}')
SAMPLER = 'Nestle'
# analysis_for_3770(np.arange(32))
evidence_for_3770(HPC = HPC)
else:
# run the nested sampling on a cluster
# the indices allow each model/channel to be run simultaneously on
# different machines. See the slurm scripts for examples
SAMPLER = 'dynesty'
analysis_for_3770(args.indices)